Machine Learning
Foundation models, fine-tuning, prompt-tuning, neural network, reinforcement learning
Table of Contents
Foundation Models (FMs)
Generative AI (GenAI) has demonstrated transformative potential across diverse domains, and is supported by large FMs such as large language models (LLMs) like ChatGPT.
Fine-tuning
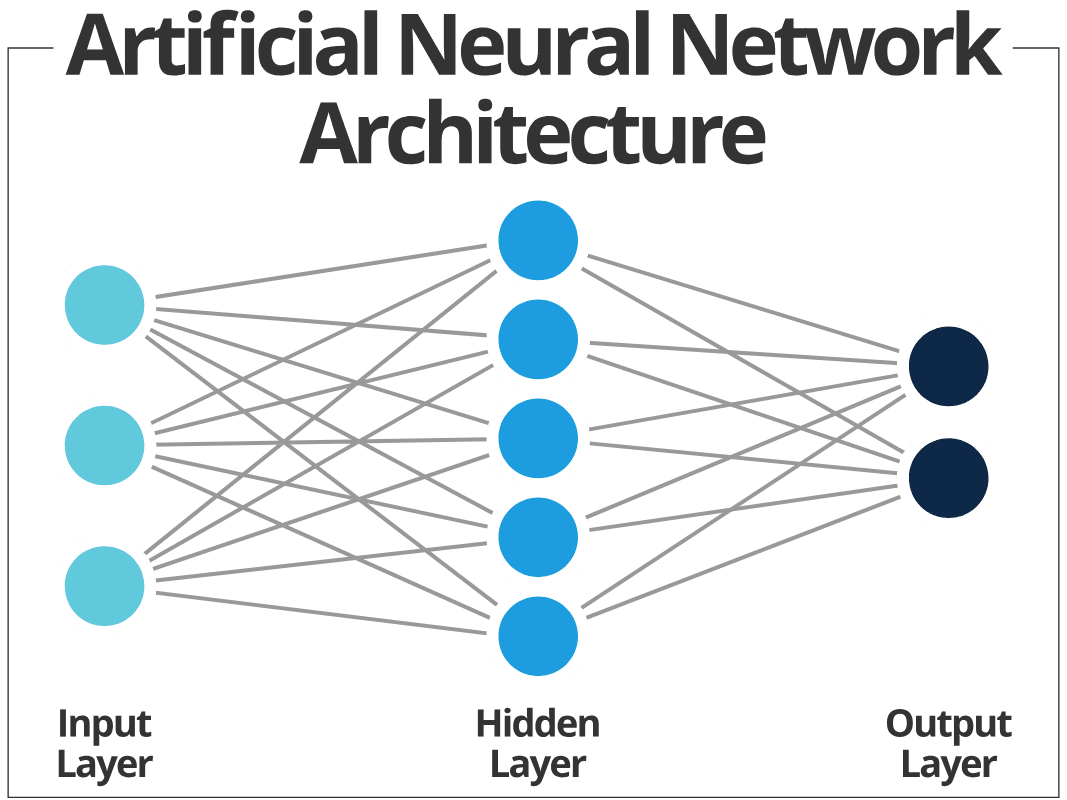
Fine-tuning is an approach to transfer learning in which the parameters of a pre-trained neural network model are trained on new data. It can be done on the entire neural network, or on only a subset of its layers. Low-rank adaptation (LoRA) is an adapter-based technique for efficiently fine-tuning models. The basic idea is to design a low-rank matrix that is then added to the original matrix.
Our related works include:
- Junjie Wang, Guangjing Yang, Wentao Chen, Huahui Yi, Xiaohu Wu, Zhouchen Lin, Qicheng Lao. “MLAE: Masked LoRA Experts for Parameter-Efficient Fine-Tuning.” Submitted.
- Jiayu Huang (my student), Xiaohu Wu, Qicheng Lao, Guanyu Gao, Tiantian He, Yew-Soon Ong, Han Yu. “Stabilized Fine-Tuning with LoRA in Federated Learning: Mitigating the Side Effect of Client Size and Rank via the Scaling Factor.” Submitted.

Prompt-tuning
Prompt-tuning is a technique in machine learning where a set of trainable inputs—called prompt tokens– are learned and added to the input of a large language model (LLM). These tokens guide the model to perform a specific task without changing any of the model’s actual weights (Yi et al., 2025).
Our other submitted works include:
- Zhu He, Haoran Zhang, Wentao Zhang, Shen Zhao, Qiqi Liu, Xiaohu Wu (coresponding author), Qicheng Lao. “Learning conceptual text prompts from visual regions of interest for medical image segmentation.” Submitted to Engineering for the second round of review.
- Xueqi Bao, Ke Li, Xiaohu Wu, Ping Ma, Qicheng Lao. “Relation-Augmented Diffusion for Layout-to-Image Generation.” Submitted.

Reinforcement Learning for decision-making and optimization

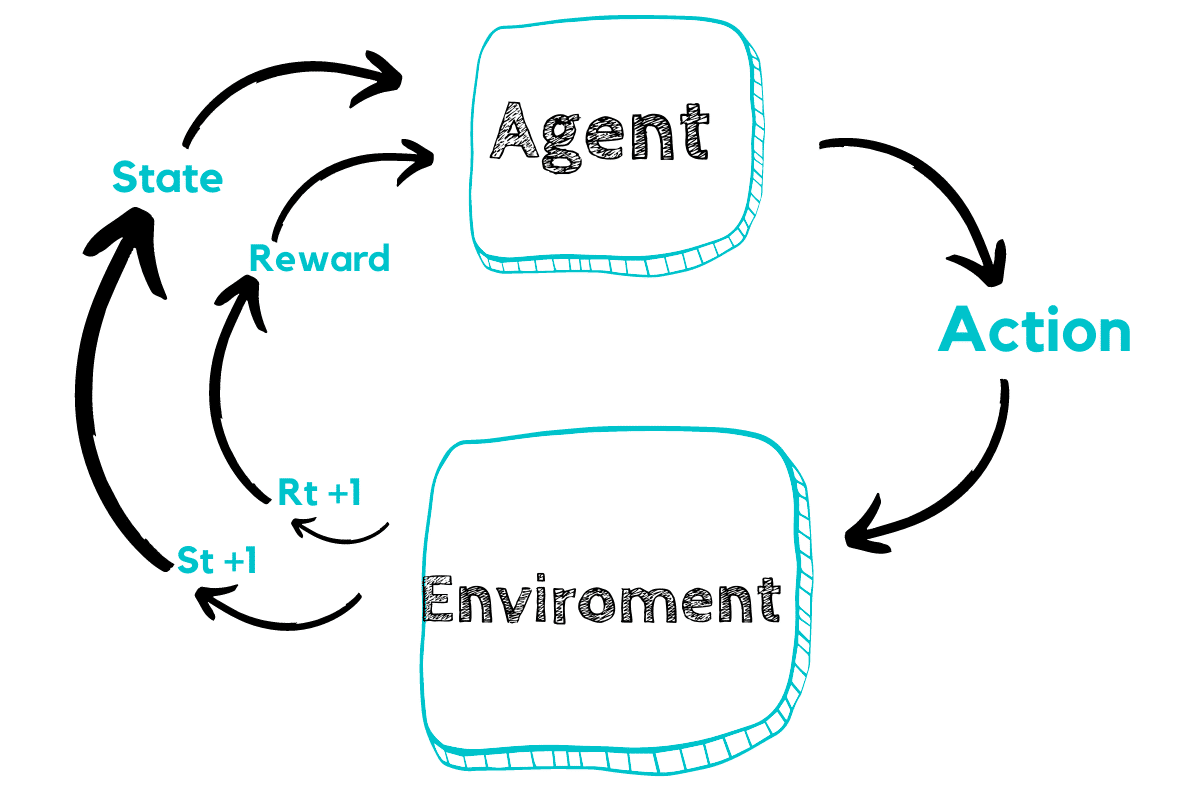
Reinforcement learning (RL) is a machine learning paradigm where an agent learns to make decisions by interacting with an environment. Through trial and error, it receives rewards for good actions and penalties for bad ones. The goal is to learn an optimal policy—a strategy—that maximizes cumulative reward over time.
In my research, I used RL for decision-making and have studied a range of related questions, including:
- Collaboration of large and small AI models: Optimizing inference delay and accuracy in cloud-edge environments (Wang et al., 2022)
- Use public clouds to cost-effectively process big-data tasks (Wu et al., 2017; Wu et al., 2019; Wu et al., 2025)
Graph Neural Networks (GNNs) using Similarity- and Dissimilarity-based Messages

We present Polarized message-passing (PMP), a novel paradigm to revolutionize the design of message-passing graph neural networks (He et al., 2024). In contrast to existing methods, PMP captures the power of node-node similarity and dissimilarity to acquire dual sources of messages from neighbors. The messages are then coalesced to enable GNNs to learn expressive representations from sparse but strongly correlated neighbors. Three novel GNNs based on the PMP paradigm, namely PMP graph convolutional network (PMP-GCN), PMP graph attention network (PMP-GAT), and PMP graph PageRank network (PMP-GPN) are proposed to perform various downstream tasks. Theoretical analysis is also conducted to verify the high expressiveness of the proposed PMP-based GNNs. In addition, an empirical study of five learning tasks based on 12 real-world datasets is conducted to validate the performances of PMP-GCN, PMP-GAT, and PMP-GPN. The proposed PMP-GCN, PMP-GAT, and PMP-GPN outperform numerous strong message-passing GNNs across all five learning tasks, demonstrating the effectiveness of the proposed PMP paradigm.
References
2025
- ICML
 iDPA: Instance Decoupled Prompt Attention for Incremental Medical Object DetectionThe 42nd International Conference on Machine Learning, 2025
iDPA: Instance Decoupled Prompt Attention for Incremental Medical Object DetectionThe 42nd International Conference on Machine Learning, 2025 - IEEE TSC
 Towards Cost-Optimal Policies for DAGs to Utilize IaaS Clouds with Online LearningIEEE Transactions on Services Computing, 2025
Towards Cost-Optimal Policies for DAGs to Utilize IaaS Clouds with Online LearningIEEE Transactions on Services Computing, 2025
2024
- AIJ
2022

2019
- IEEE TPDS Toward designing cost-optimal policies to utilize IaaS clouds with online learningIEEE Transactions on Parallel and Distributed Systems, 2019
2017
- IEEE ICCAC Toward designing cost-optimal policies to utilize IaaS clouds with online learning2017 International Conference on Cloud and Autonomic Computing (ICCAC). Conference information , 2017